### 内容主体大纲1. **引言** - 虚拟币的普及背景 - 钱包在虚拟币交易中的重要性2. **虚拟币钱包的类型** - 热钱包与冷...
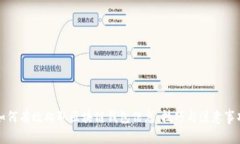
区块链钱包是一种用于存储和管理数字资产(如比特币、以太坊等)的工具。这类钱包的核心功能包括生成新的数字地址、接收和发送数字货币、查看余额及交易历史等。由于区块链具备去中心化和不可篡改的特性,用户的资产安全性相对较高。
### 1.2 爬取区块链钱包信息的必要性随着区块链技术的普及,越来越多的人对数字资产的管理和查询产生了兴趣。爬取区块链钱包信息不仅能够帮助用户获得实时的数据,还可以为研究机构提供数据支持,从而使他们能更好地理解市场动态。无论是为了学术研究、市场分析,还是为了商业决策,爬取区块链钱包信息都是一项重要的工作。
--- ## 区块链钱包的信息类型 ### 2.1 钱包地址钱包地址是一串字母和数字组合的字符串,唯一标识一个钱包。在区块链中,每个钱包都可以产生多个地址用于接收和发送交易。
### 2.2 交易记录交易记录包括所有与该钱包相关的交易信息,如发送和接收的金额、时间戳以及交易哈希。这些信息可以帮助用户分析其资产的变化和交易历史。
### 2.3 余额信息余额信息显示某个钱包中当前可用的数字资产量。这一信息对于用户了解其资产状况至关重要。
### 2.4 其他相关信息包括钱包的创建时间、关联账户信息、安全性设置等。这些信息有助于用户更全面地了解其数字资产的管理状况。
--- ## 爬取区块链钱包信息的基本方法 ### 3.1 API接口许多区块链平台提供API接口,允许开发者用程序化的方式访问数据。这种方法通常比较简单,且输出格式标准化,易于使用。
### 3.2 爬虫技术对于没有API接口的平台,爬虫技术可以用于直接从网站上抓取信息。这需要一定的代码能力和对网页结构的理解。
### 3.3 数据库访问区块链数据往往存储在数据库中,研究者可以通过数据库查询语言进行数据提取。这种方法要求用户具备比较专业的知识。
--- ## 技术实现步骤 ### 4.1 环境配置为爬取区块链钱包信息,需要配置相应的开发环境,包括安装Python和爬虫框架,如Scrapy或BeautifulSoup。
### 4.2 编写爬虫代码根据目标网站的结构,编写爬虫代码以获取所需的信息。应掌握相关的网络请求、数据解析等技能。
### 4.3 数据存储与维护爬取的数据需要存储在数据库中,以便后续的分析与查询。定期更新和维护是确保数据有效性的前提。
--- ## 存在的法律与伦理问题 ### 5.1 数据隐私在爬取区块链钱包信息时,需要关注用户的隐私保护,避免获取敏感数据。遵循GDPR等相关法律法规是必要的步骤。
### 5.2 遵循法律法规不同国家和地区对于数据爬取有不同的法律规范,必须确保所采取的方法合法合规。
--- ## 实际案例分析 ### 6.1 成功的爬取案例举例说明一个成功的案例,描述背景、方法及结果,以验证数据爬取的重要性与有效性。
### 6.2 失败的爬取案例及教训分析一个失败的案例,探讨其中的问题与教训,以帮助读者避免类似错误。
--- ## 常见问题解答 ### 7.1 什么是区块链钱包?区块链钱包是一种用于存储、发送和接收数字货币的工具,其主要功能包括生成地址、查看余额和交易历史等。
### 7.2 如何选择合适的爬取方式?选择爬取方式时,应考虑目标网站的访问限制、可用的API以及自身的技术能力。如果有API接口,优先使用API;若没有,则可考虑爬虫技术。
### 7.3 有哪些常见的爬虫框架?常见的爬虫框架包括Scrapy、BeautifulSoup和Requests等。Scrapy适合大规模爬取,而BeautifulSoup则适合简单的网页解析。
### 7.4 爬取区块链钱包信息面临哪些挑战?挑战主要包括网站的反爬机制、数据的准确性与完整性、法律法规的合规性等。需要针对这些问题进行相应的策略调整。
### 7.5 如何确保数据的准确性与合法性?确保证数据准确性的方法包括定期验证、使用可靠的数据源和技术手段等;而确保合法性则需要遵循相关的法律法规。
### 7.6 爬取后的数据如何处理与利用?爬取后,可将数据存储在数据库中,进行分析和可视化,形成报告或图表,为决策提供支持。
--- 接下来的内容,请根据大纲逐段逐步详细展开,确保全面涵盖爬取区块链钱包信息的技术、法律和应用等多方面的知识,满足3500字的要求。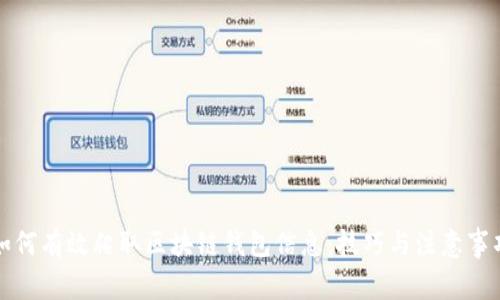

### 内容主体大纲1. **引言** - 虚拟币的普及背景 - 钱包在虚拟币交易中的重要性2. **虚拟币钱包的类型** - 热钱包与冷...

## 内容主体大纲1. 引言 - 简介比特币及其钱包的重要性 - 介绍手机版比特币钱包的优势2. 比特币钱包的基本知识 - 什...

随着全球范围内数字货币的迅猛发展,俄罗斯在加密货币领域的探索和实践逐渐受到关注。近年来,随着区块链技术...

## 内容主体大纲1. 引言 - 区块链技术的兴起 - 数字货币的普及与需求2. 区块链美元钱包的概念 - 什么是美元钱包? ...